Over the last few years I have use a combination of Rmarkdown and beamer to create slides for my teaching. Overall, I love the ability to abstract away from overly crufty beamer code and write in a more compact and natural way. The downside is that I often run into frustration trying to get some part of the slides just so.
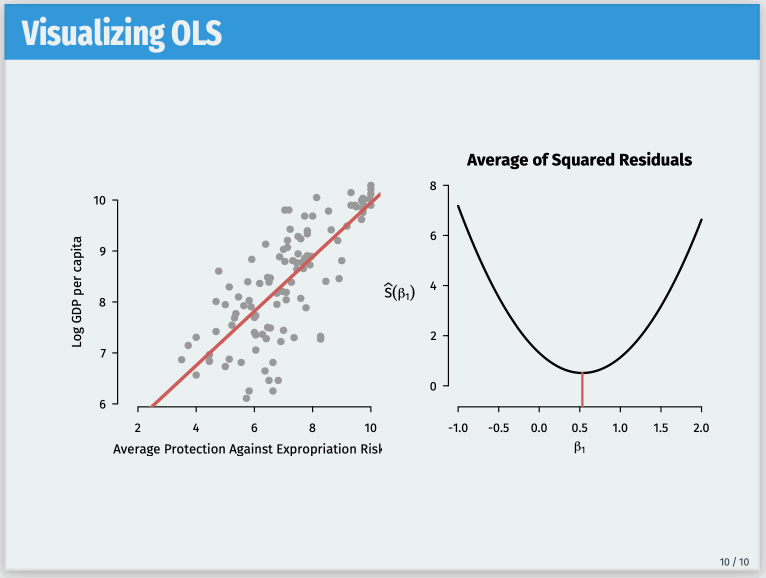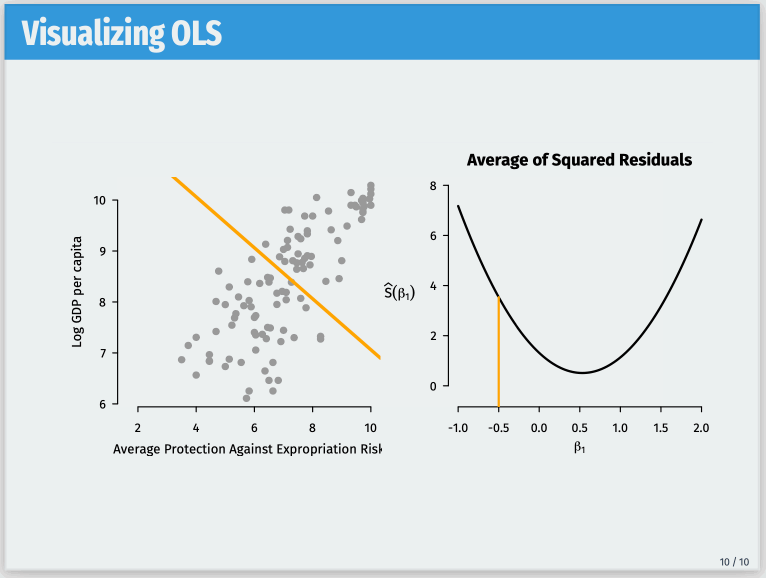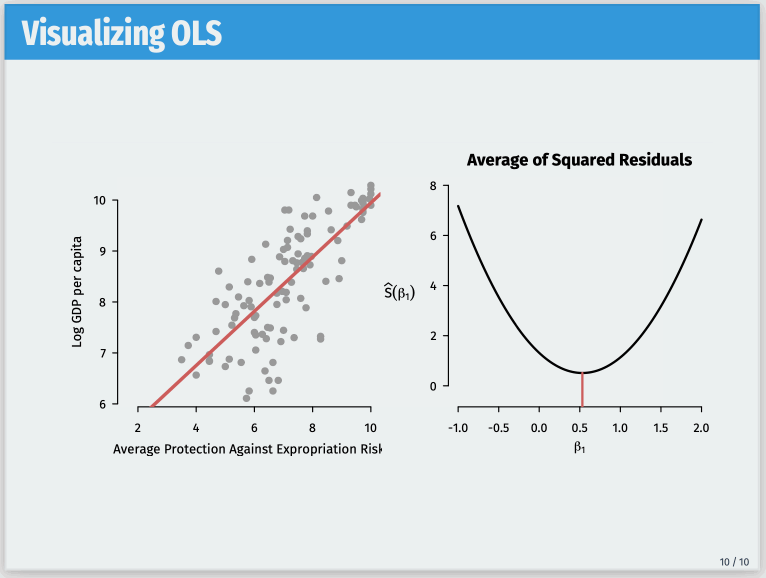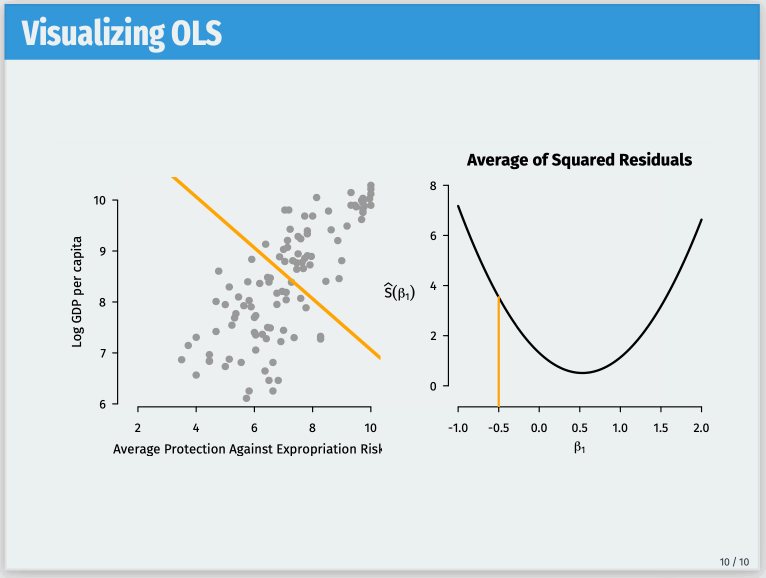
One such frustration comes with overlays for figures. Often, I want a single frame to contain multiple overlays with different PDF files replacing one another. A (moving) picture is worth a thousand words here, so this is the goal I’m trying to achieve:
Earlier today, on Twitter, I made the claim that Achen’s “A Rule of Three” (often referred to as ART) is “insanely misleading.” Brevity is not always clarity, so I wanted to follow up.
A Rule of Three (ART): A statistical specification with more than three explanatory variables is meaningless.
Strong words, obviously, given the usual number of variables in a statistical model. Does this mean that three variables provide “enough” control? In actuality, Achen’s answer is “no” and this supposition forms that basis for his reasoning:
If one needs several more controls, then there is too much going on in the sample for reliable inference.
Inherently, three variables is not enough for most data situations, so just dropping K-3 variables from a given regression wouldn’t quite work or get to Achen’s point. His more subtle point is that causal heterogeneity in most samples hinders the ability to make valid or reliable inferences. Thus, Achen’s actual advice (at least in this paper) is to subset the data to a level such that only three variables are needed:
Contrary to the received wisdom, it is not the “too small” regressions on modest subsamples with accompanying plots that should be under suspicion. Instead, the big analyses that use all the observations and have a dozen control variables are the ones that should be met with incredulity.
Achen’s point is not that we should only control for three variables, but rather that our statistical models should only include (and only need to include) three variables. We should “control for” other variables by stratification/subsetting the data. Interestingly, this critique is similar to causal inference scholars crying foul at the “constant effects” assumption inherent in many structural equation models. And the remedies are similar as well: make “small” comparisons within subgroups is exact what those causal inference folks are advocating (they just want to average across the subgroups, perhaps Achen would prefer not to, I’m not sure).
The point I do not see Achen making here is that more control is bad. He wants to control for many factors, just not by including them in a model. He would rather account for them by stratification. Which is great! But it actually doesn’t get around the problems of post-treatment bias. Selecting your sample based on a post-treatment variable is equivalent in terms of bias to controlling for a post-treatment variable in a regression.
You can find a good discussion of this type of post-treatment/selection bias in Chapter 8 of the Hernán and Robins Causal Inference text. Also, in Cyrus Samii’s blog post and slides.
Continue reading...If you asked me to describe the rising philosophy of the day, I’d say it is data-ism. We now have the ability to gather huge amounts of data. This ability seems to carry with it certain cultural assumptions — that everything that can be measured should be measured; that data is a transparent and reliable lens that allows us to filter out emotionalism and ideology; that data will help us do remarkable things — like foretell the future.
First, the revolution isn’t really in data, it’s in analysis. Most of the innovation in the last 15 years or so has come from the analysis side. Think PageRank: crawlers already existed, but it was the clever analysis of the raw data that made it valuable.
Second, I’m pleasantly amused by Brooks’s wariness of cultural assumptions. Even the most quantitative of scholars has those areas where quantification unsettles the nerves (ask quantitative academics about teaching evaluations if you want a sense of this). And, in general, quantitative scholars advance arguments in support of data on qualitative grounds. Gelman’s blog is rife with examples of (what he calls) “qualitative” or “sociological” evidence of some point about research. This is hardly a criticism since to evaluate the effectiveness of data-driven approaches with a data-driven approach would either be tautological or (at best) unpersuasive to data skeptics.
Of course, as Brooks outlines in his column, the best arguments for quantitative approaches are found in studies themselves.
Continue reading...…it’s just part of a general attitude people have that there is a high-tech solution to any problem. This attitude is not limited to psychologists. For example, Bannerjee and Duflo are extremely well-respected economists but they have a very naive view (unfortunately, a view that is common among economists, especially among high-status economists, I believe, for whom its important to be connected with what they view as the most technically advanced statistics) of what is important in statistics.
What other disciplines find useful from statistics may or may not be interesting (or intelligible!) to you and that’s completely fine. One discipline’s overly-complex model is another discipline’s deeply intuitive bread and butter. Models and methods can be useful whether or not you as a reader understand them.
The Gelman post led Michael Tofias to try and define the complex model sweet spot:
@drewlinzer a model should be simple enough so that we can understand how and when it's wrong.
I generally think this is good advice for someone using a model. It’s your model and if you break it, you buy it. But this advice is shaky in at least one common situation. Think of the bootstrap, which is a clever way of estimating confidence intervals and standard errors. Most people, even those who use it often, have no idea when or why the bootstrap fails. Does this mean that people shouldn’t use the bootstrap? Probably not.
There is often a wide chasm between what you consider “simple” and what others consider “simple”. Double the width of that chasm for “intuitive”. It’s up to modelers to bridge those gaps. Unfortunately, Gelman’s quote above instead widens those gaps by dismissing what’s on the other side (the MATH over in that camp, have you seen it?). We roll our eyes pundits when they rail against the use of models at all in politics and yet here is one of our own dismissing more complicated models in academia.
Continue reading...PDFs are the workhorse of academic life. If there isn’t a PDF open on my computer, it probably means I am not working. But as screens are becoming increasingly important, the PDF remains almost nostalgically loyal to the printed page. This tension is harming researchers’ ability to get their work read inside and outside the academic community. If I’m being honest, I basically want to actually be able to read academic writing on my phone and right now that experience is horrible, bordering on impossible.
The PDF was useful when we needed some way of transferring a paper electronically without any loss of content or formatting. It mimics the process of physically mailing a paper from one researcher to another. It provides a massive improvement over Microsoft Word, where content and formatting could easily be lost in the transfer process. It also has an inherent reading model in mind—the PDF represents the physically printed document and lends itself to printing a hard copy. The PDF begs to be printed—it is already on pages that match your printer paper, it already has a white background like your printer paper, and so on.
But these advantages—fidelity to the physical document, a fixed format—are becoming liabilities. We live in an era of massive diversity in screen size and resolution. I am just as likely to stumble on a new paper on my phone as I am on my laptop as I am on my rather large monitor. The fixed format of the PDF cannot cope with this diversity because it remains loyal to the printed page rather than the reader. And obviously this is beneficial when reviewing proofs for publication, but when trying to increase readership, should we rely on a format that is so rigid and unhelpful to readers?
HTML is a another standard that most everyone that has access to the internet uses every day. It takes a different approach than PDFs. Ignore the printed page and focus on screens, where the reading is meant to take place. There is a strange divide emerging among academics, especially those who blog. They post their “non-academic” thoughts (largely on academic topics) in HTML on a blog or on their own website. At the same time, they keep their “professional” or “academic” writing in PDFs on their academic website. There is an implicit admission that HTML are better than PDFs for discovery and reading, but this hasn’t trickled back to their academic work. I am as guilty of this as the next person.
All of this stems somewhat from a lack of tools. LaTeX provides the ability to create high-quality PDFs, rich with mathematical text, high-quality typesetting, and bibliographic support. There are methods, such as Pandoc, that can convert LaTeX to HTML (and services like MathJax can handle the mathematical type), but these methods are not yet standard and don’t always work as planned. Maybe this will change quite rapidly, but I’m not optimistic. Academic are known for many things, but rapid changes are not among them.
Continue reading...